Thanks for your feedback!
EDIT
El interceptor Rate Limit AI Tokens se puede utilizar en proxies de APIs que consumen Grandes Modelos de Lenguaje (Large Language Models - LLMs) para controlar el consumo de tokens por parte de las aplicaciones de inteligencia artificial. De esta forma, es posible aumentar la eficiencia del negocio gestionando mejor los costes de estas aplicaciones y evitando su uso excesivo, así como mantener la calidad del servicio evitando sobrecargas en los sistemas de inteligencia artificial.
A continuación aprenderás cómo incluir el interceptor Rate Limit AI Tokens en el flujo de sus APIs y cómo configurarlo.
El interceptor Rate Limit AI Tokens permite definir la cantidad máxima de tokens permitidos en un periodo de tiempo. Cuando este límite es excedido, la llamada será denegada y una respuesta con código HTTP 429 será devuelta al cliente. Se puede establecer un porcentaje adicional de llamadas que se aceptarán por encima del límite especificado y también optar por enviar un parámetro con el número de tokens restantes en el header de la respuesta.
|
La contabilización de tokens realizada por el interceptor Rate Limit AI Tokens es sólo una estimación y funciona de forma similar a la herramienta OpenAI Tokenizer. Por lo tanto, si su API está directamente conectada al body enviado al LLM, el valor calculado por el interceptor puede no coincidir con el calculado por la API de OpenAI. Esto puede deberse a que la API de OpenAI, además de la string correspondiente al contenido del mensaje (prompt), también tiene en cuenta otros elementos presentes en el body de la petición a la hora de calcular los tokens consumidos. La propia OpenAI advierte en este artículo de la dificultad de estimar el número de tokens. |
El interceptor puede incluirse en los flujos de petición (REQUEST TO BACKEND) de una revisión de API o de un plan, para todos los recursos (resources) y operaciones (operations) o para recursos y operaciones específicos.
| Vea más sobre flujos de API. |
Para insertar el interceptor Rate Limit AI Tokens en el flujo, haga clic en su icono, situado en la categoría AI de la pantalla Edit Flow, y arrástrelo hasta el flujo de petición (REQUEST TO BACKEND), como en la animación siguiente:
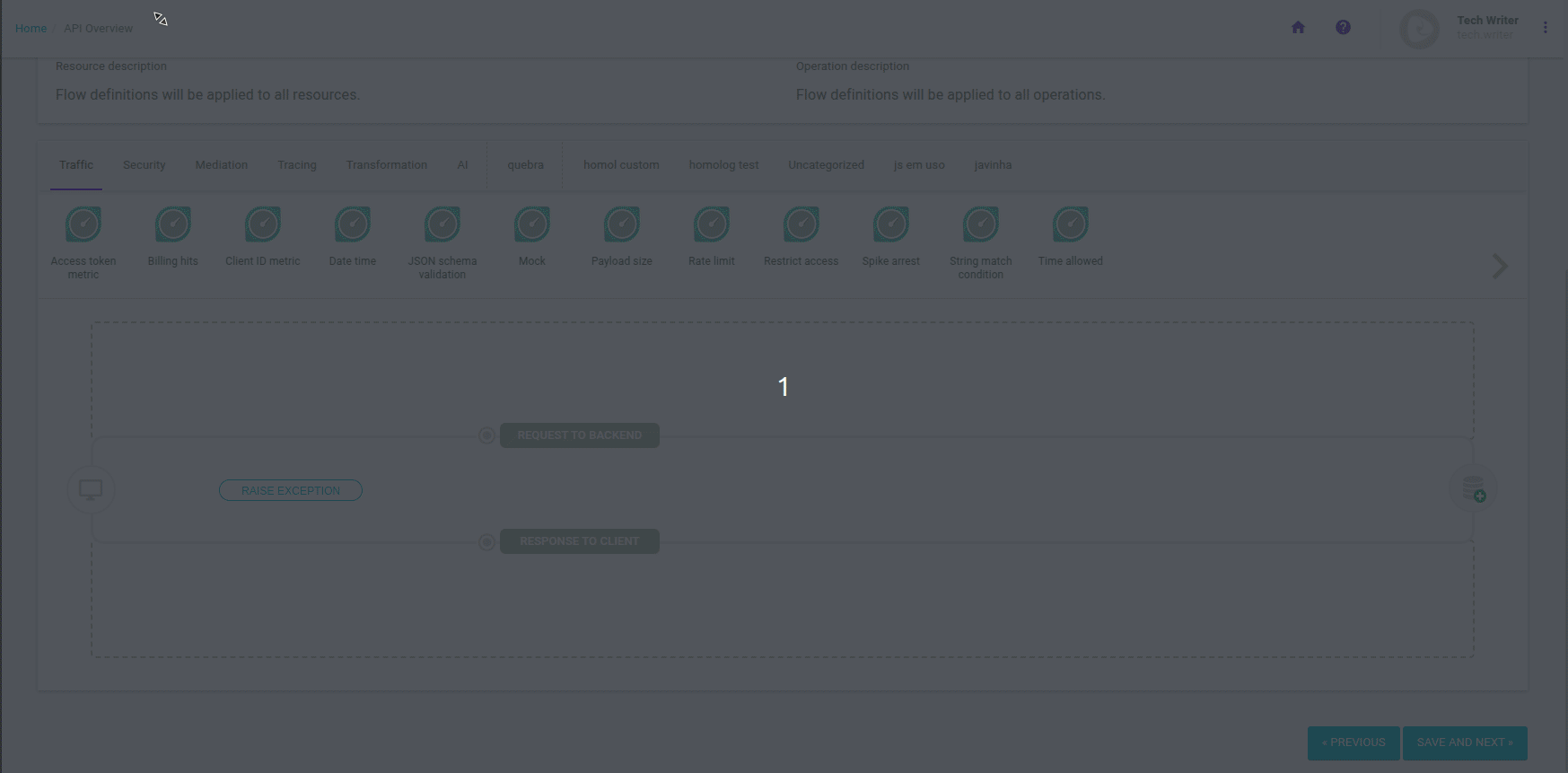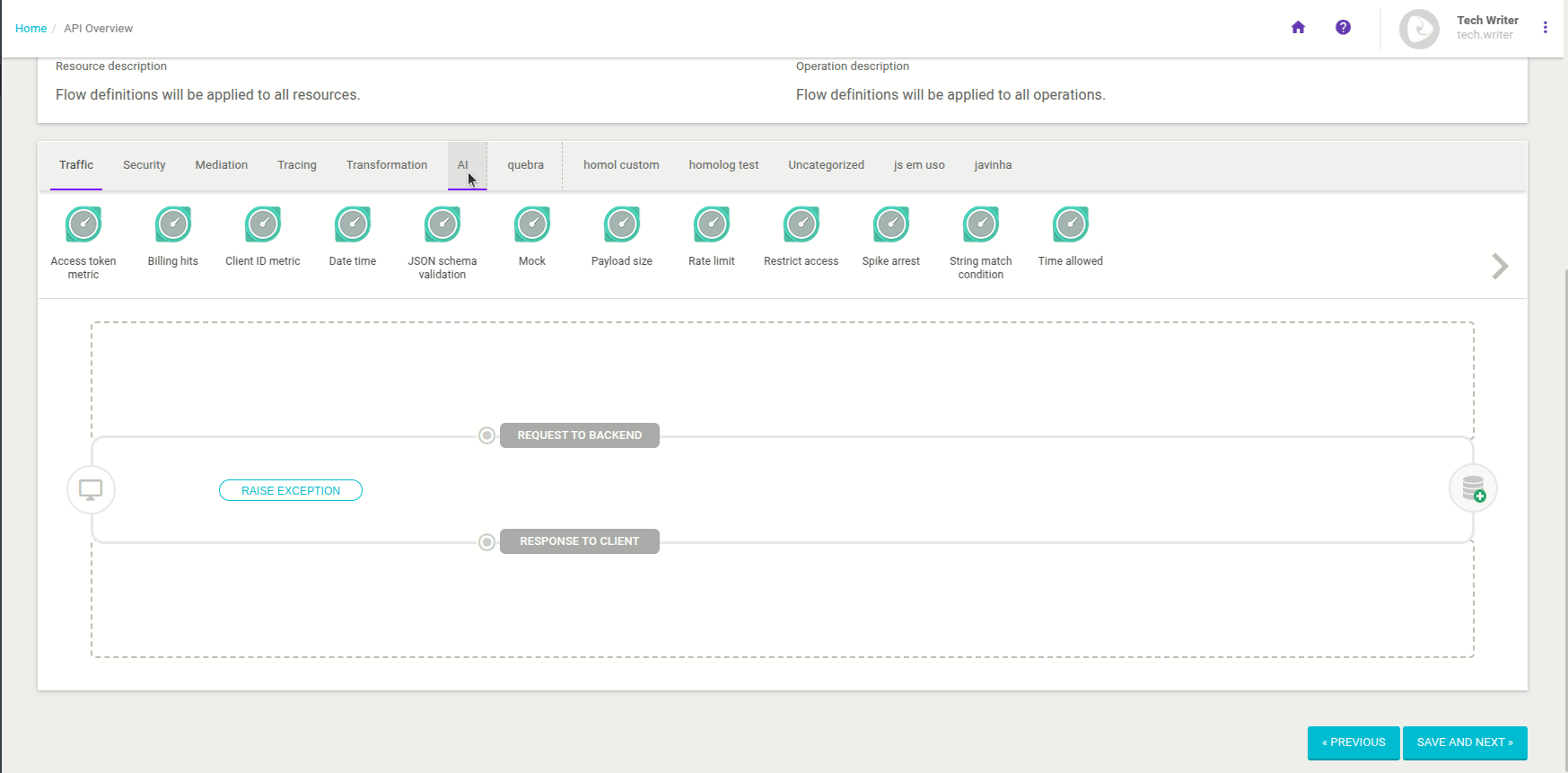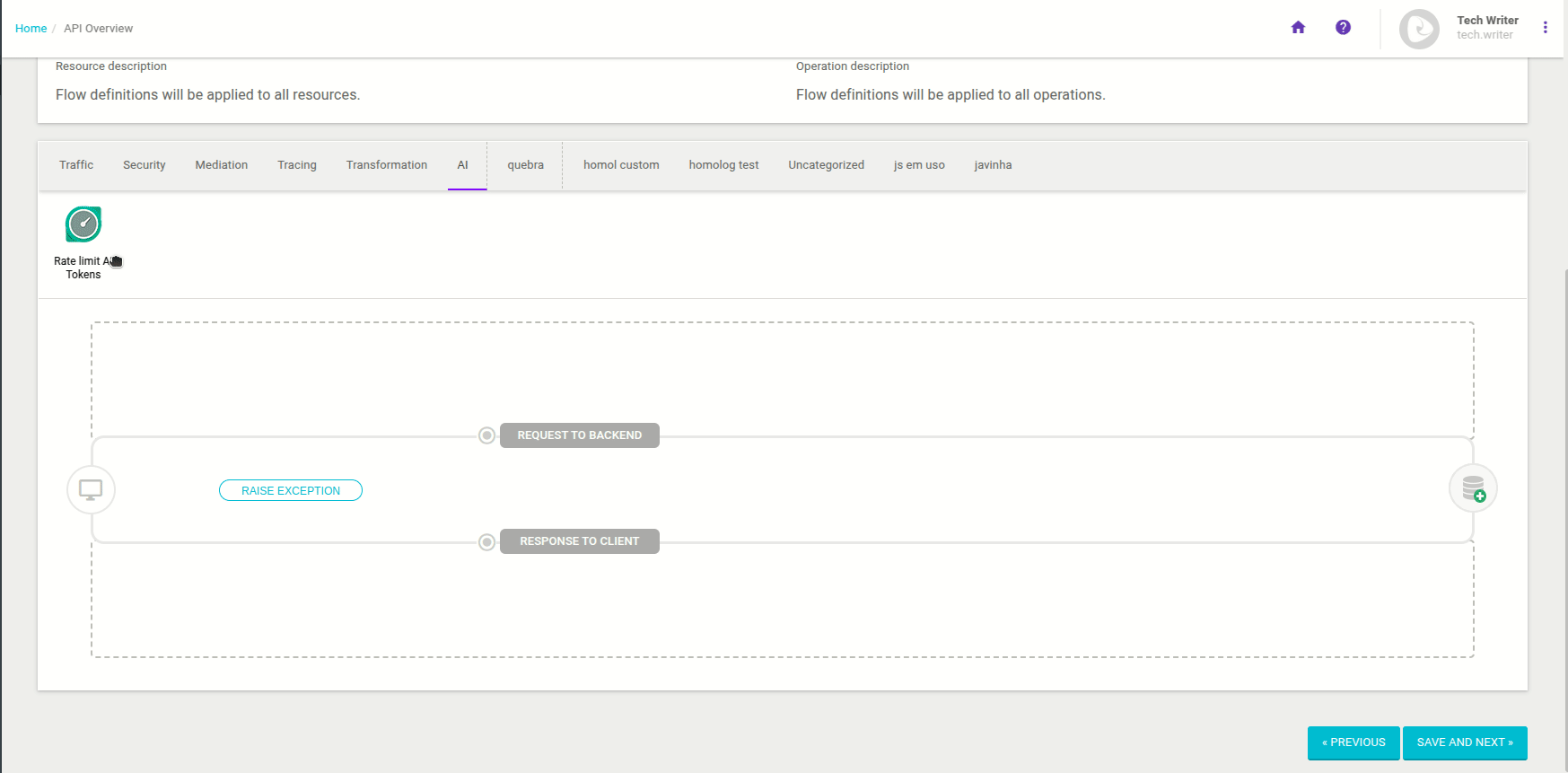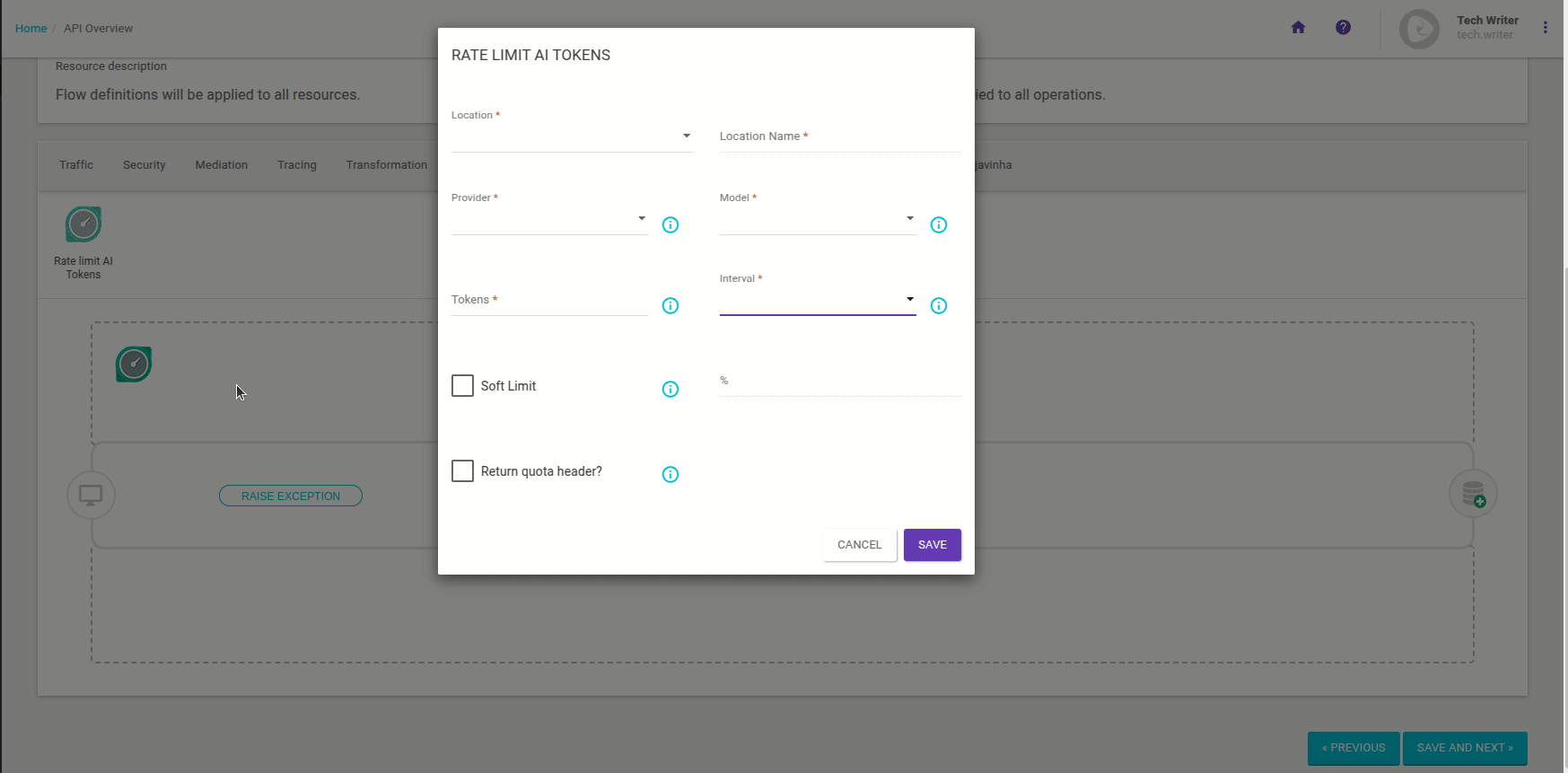
Se abrirá una ventana modal para que usted proporcione la siguiente información:
Location: seleccione la ubicación en la petición donde se enviará la información sobre los tokens (Cookie, Header, Query Param o JSON Body).
Location Name: introduzca el nombre del campo seleccionado en Location.
En el caso de JSON Body, puede introducir el nombre exacto de un campo del JSON o utilizar expresiones JSONPath, que permiten acceder a campos o arrays de forma dinámica y flexible en estructuras JSON complejas.
Vea ejemplos de uso de este campo.
Provider: seleccione el proveedor del LLM utilizado (por el momento, sólo se aceptan los modelos proporcionados por OpenAI).
Model: seleccione el LLM utilizado.
Tokens: introduzca el número máximo de tokens aceptados en el periodo de tiempo especificado.
Interval: seleccione el intervalo de tiempo dentro del cual se aceptará el número máximo de tokens especificado.
Soft Limit: permite establecer un porcentaje adicional de tokens que se aceptarán. Para ello, marque la casilla de verificación y añada el valor deseado en el campo % a la derecha.
|
Si la opción Soft Limit es marcada, el campo % se convierte en obligatorio. De lo contrario, el interceptor funcionará normalmente, basándose en el límite establecido en el campo Tokens. |
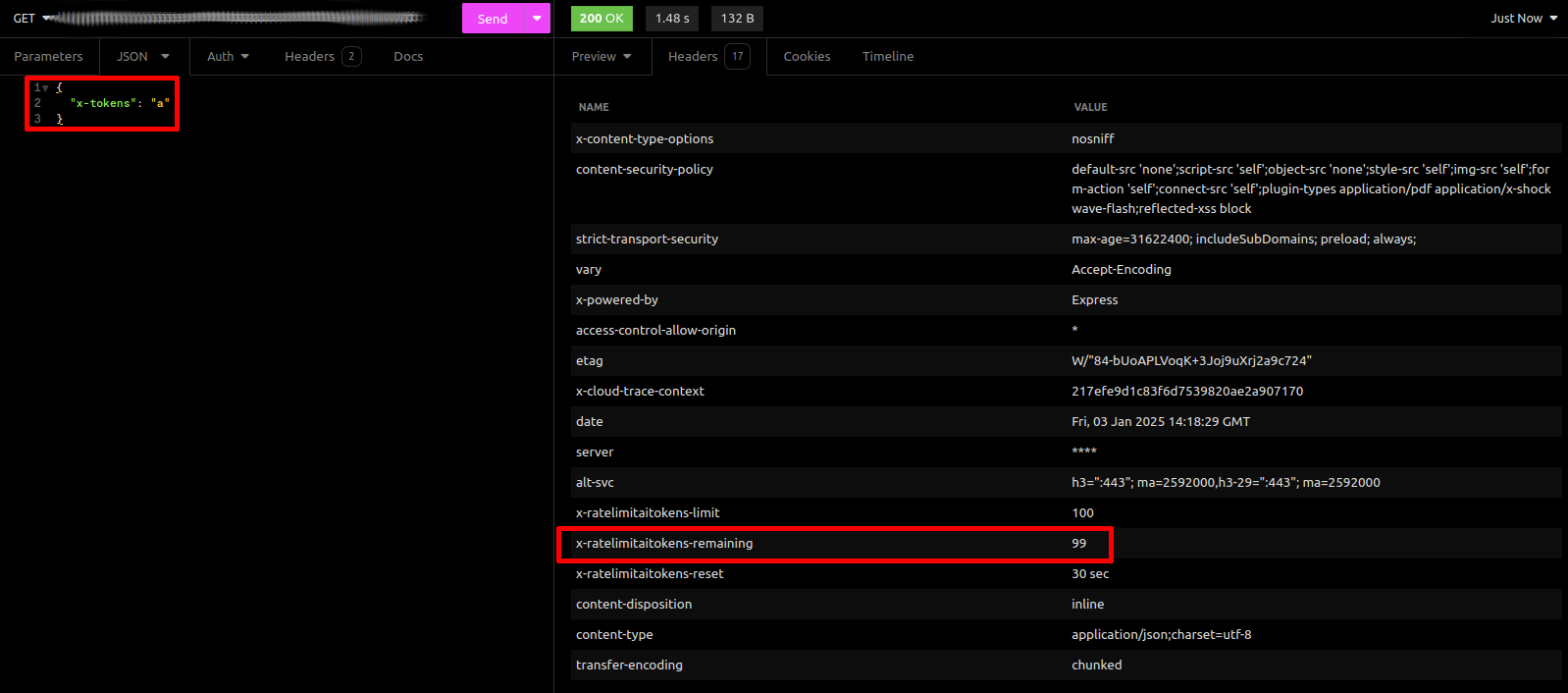
Return quota header?: si se marca, se enviará un parámetro con el número de tokens restantes con el header de la respuesta, como en la imagen siguiente:
|
Cualquier tipo de dato que vaya a ser procesado por el interceptor, ya sea código, JSON o texto estructurado, debe ser convertido a string antes de ser enviado. Si el valor no es una string:
¿Por qué se produce el bypass? El interceptor sólo puede calcular tokens para valores de tipo string. Los campos que son arrays, objetos, valores nulos u otros tipos no pueden ser procesados. Por lo tanto, para evitar fallos en las peticiones en estos casos, la configuración del interceptor Rate Limit AI Tokens simplemente se ignora. ¿Cómo evitar el bypass? Asegúrese de que el campo evaluado es siempre una string. En el caso de objetos o arrays, utilice la serialización o extraiga los valores necesarios con herramientas como JSONPath (ver más abajo), asegurándose de que el resultado es una string.
La contabilización de tokens no se realiza directamente en objetos o arrays. Todo el contenido debe ser serializado como una string, ya que la propia API de OpenAI sólo acepta strings.
Si desea calcular los tokens de un campo específico dentro de un JSON, debe indicar claramente el campo deseado (utilizando el nombre literal o una expresión JSONPath, como se ejemplifica a continuación). Es esencial que el valor extraído sea una string. |
Al seleccionar JSON Body en el campo Location del formulario de configuración del interceptor, existen dos posibilidades para el campo Location Name:
Nombre exacto del campo: Introduzca directamente el nombre exacto del campo deseado en el JSON.
Expresión JSONPath: Introduzca una expresión que comience por $. para acceder a los datos en el JSON de forma dinámica.
Si el valor introducido comienza por $., se interpretará como una expresión JSONPath.
En caso contrario, se tratará como el nombre exacto de un campo del JSON en el nivel raíz.
Vea a continuación algunos ejemplos:
{
"model": "gpt-4o",
"version": "v1.0",
"content": "Qual é o clima hoje?"
}
Campo literal: content → Resultado: Qual é o clima hoje? (total: 6 tokens, 20 caracteres)
JSONPath: $.content → Resultado: Qual é o clima hoje? (total: 6 tokens, 20 caracteres)
JSON de entrada:
{
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "Responda sempre com ironia"
},
{
"role": "user",
"content": "Aqui está um JSON, você pode me ajudar a entender os itens?\n\n{\"items\": [{\"id\": 1, \"value\": \"primeiro\"}, {\"id\": 2, \"value\": null}, {\"id\": 3}]}"
}
]
}
Campo literal: messages → Resultado: se ignorará el cómputo, porque messages es un array, no una string.
Campo literal: model → Resultado: gpt-4o (total: 5 tokens, 6 caracteres)
JSONPath: $.messages[*] → se ignorará el cómputo, porque messages es un array de objetos, no una string.
Cuando se utilizan alternativas como $.messages[*], se devolverá el array completo, lo que provoca un bypass, ya que el resultado debe ser una string.
JSONPath: $.messages[0].content → Resultado: Responda sempre com ironia (total: 7 tokens, 26 caracteres)
JSONPath: $.messages[1].content → Resultado: Aqui está um JSON, você pode me ajudar a entender os itens?\n\n{\"items\": [{\"id\": 1, \"value\": \"primeiro\"}, {\"id\": 2, \"value\": null}, {\"id\": 3}]} (total: 54 tokens, 157 caracteres)
JSONPath: $.messages[*].content → Resultado: Responda sempre com ironia + Aqui está um JSON, você pode me ajudar a entender os itens?\n\n{\"items\": [{\"id\": 1, \"value\": \"primeiro\"}, {\"id\": 2, \"value\": null}, {\"id\": 3}]} (total: 61 tokens, 183 caracteres)
JSONPath con condicional:
$.messages[?(@.role=="user")].content
messages: El nombre del array en el JSON.
[?(@.role=="user")]: Un filtro condicional que comprueba si el campo role tiene el valor "user".
@: Representa el elemento actual en el array.
role=="user": La condición que comprobamos.
.content: El campo que queremos extraer del objeto que cumplía la condición.
Resultado (total: 54 tokens, 157 caracteres):
Aqui está um JSON, você pode me ajudar a entender os itens?\n\n{\"items\": [{\"id\": 1, \"value\": \"primeiro\"}, {\"id\": 2, \"value\": null}, {\"id\": 3}]}
{
"user": {
"id": 123,
"profile": {
"name": "João",
"preferences": {
"notifications": true
}
}
}
}
Campo literal: user → se ignorará la contabilización porque user es un objeto, no una string.
JSONPath: $.user.profile.name → Resultado: João (total: 2 tokens, 4 caracteres)
JSONPath: $.user.profile.preferences.notifications → Resultado: true (total: 1 token, 4 caracteres)
{
"items": [
{"id": 1, "value": "primeiro"},
{"id": 2, "value": null},
{"id": 3}
]
}
Campo literal: items → se ignorará la contabilización porque items no es una string.
JSONPath: $.items[*].value → Resultado: ["primeiro", null] (total: 2 tokens, 8 caracteres)
JSONPath: $.items[?(@.id==2)].value → Resultado: [null] (total: 0 tokens, 0 caracteres)
JSONPath: $.items[3].value → Resultado: Se lanzará una excepción con un código de estado HTTP 400 (Bad Request) indicando que no se ha encontrado el campo.
Share your suggestions with us!
Click here and then [+ Submit idea]