Thanks for your feedback!
EDIT
Agregaciones optimizan búsquedas complejas, haciéndolas más rápidas y sencillas. Se pueden agregar varias búsquedas, realizándose y mostrándose como una sola solicitud y resultado final. Esto aumenta el rendimiento y mejora la experiencia del usuario. En comparación con las consultas (queries), las agregaciones consumen más CPU y memoria.
Cada agregación es una combinación de uno o más buckets y cero o más métricas.
Vea más sobre:
Los bucket sirven para organizar documentos en grupos con base en ciertos criterios, según el tipo de agregación. El concepto surge de la idea de recoger documentos en baldes (traducción de cubetas). Buckets no calcula métricas como lo hace metrics.
Como ejemplos de agrupación en buckets: la fecha 2022-12-19 estaría en el bucket (balde) December (diciembre) y la ciudad de Campinas, en el bucket del estado de São Paulo.
Los buckets pueden estar contenidos dentro de otros buckets. Por ejemplo, Campinas entraría en el bucket del estado de São Paulo y todo el bucket de São Paulo estaría en el bucket de Brasil.
Consulte la siguiente tabla para obtener la descripción de los principales tipos de buckets. La imagen abajo muestra una parte de la pantalla Visualize con la lista para elegir el tipo de bucket. Consulte también cómo crear una nueva visualización y aprenda cómo llegar a esta pantalla para elegir el tipo de bucket.
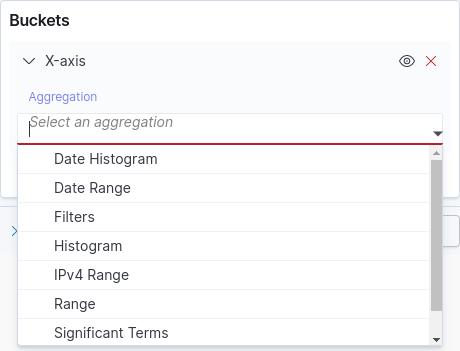
Tipo |
Definición |
Parámetros |
Histograma (histograma) |
Agrupa documentos en buckets dinámicamente en función de rangos específicos (valores numéricos o rangos numéricos). Similar a la agregación por range; sin embargo, en lugar de especificar cada intervalo de forma específica, puedes activar la opción |
Minimum interval: Seleccione Use auto interval o especifique el intervalo mínimo. |
Date histogram (histograma de fecha) |
Similar al histograma simple, pero solo se usa con valores de fecha o intervalo de fechas. |
Minimum interval: especifique el intervalo de redondeo mínimo. Por defecto, |
Range (rango) |
Define un conjunto de intervalos, cada uno de los cuales representa un bucket. Cada documento se revisa según el rango de variación de su intervalo y se agrupa según su relevancia o correspondencia con este rango, que puede ser numérico, de fechas o de dirección IP. Ejemplo de uso: al buscar un determinado tipo de producto en una tienda en línea, range puede mostrar el rango de precios más popular para ese tipo de producto. |
|
Date range (rango de fechas) |
Agregación de rango específico a fechas. |
Acceptable date formats: Determine el inicio y final del rango. |
Filters (filtros) |
Agregación donde cada bucket contiene documentos que coinciden con una consulta. Es posible definir más de un filtro. |
Filter: proporcione la expresión de búsqueda. Puede escribilo en DQL o Lucene. Haga clic en + Add filter para agregar otro filtro. |
NOTE: Seleccione Lucene o DQL y utilice una sintaxis correspondiente. Para que una consulta escrita en Lucene se interprete correctamente, es necesario seleccionar Lucene. Lo mismo es válido para DQL. |
||
Terms (términos) |
Agrupa por categorías y recupera el número total de documentos en cada categoría. Es decir, terms le indica el número de veces que aparece un determinado vocablo en sus documentos. |
Order by defina el tipo de orden en función de la métrica (metrics) seleccionada, que puede ser: |
Significant terms (vocablos significativos) |
Devuelve ocurrencias de vocablos significativos o inusuales. El resultado que se muestra es la diferencia entre la aparición de un vocablo en todo el índice y la aparición del mismo vocablo en sus resultados de búsqueda (queries), destacando los vocablos que son relevantes dentro de cada contexto de búsqueda. Por ejemplo, el vocablo "sensedia" sería relevante en el contexto de "apis". |
Size: Defina cuántos term buckets deben devolverse de la lista total de terms. |
Las agregaciones de metrics y buckets le permiten agregar parámetros avanzados.
Para acceder a los parámetros avanzados, haga clic en el icono de expandir/contraer junto a Advanced (imagen a continuación).
Dependiendo del tipo o campo seleccionado para la agregación, además del campo para inserción en formato JSON, pueden estar disponibles diferentes opciones para ingresar o seleccionar datos.
Vea en la siguiente tabla las definiciones y los ejemplos de uso de los principales parámetros avanzados de las agregaciones de bucket.
Las definiciones de cada tipo de agregación de bucket y sus parámetros básicos se encuentran en la tabla anterior.
Tipo |
Parámetros avanzados |
Date histogram |
|
Range y Date range |
"missing": "1976/11/30",
"ranges":[
{
"key": "Older",
"to": "2015/01/01"
},
]
|
Filtros |
|
Histograma |
"histogram": {
"field": "quantity",
"range": 10,
"missing": 0
}
"extended_bounds" : {
"min" : "2014-01-01",
"max" : "2014-12-31"
}
|
Terms and Significant terms |
|
Las agregaciones de tipo Metrics extraen estadísticas de documentos agrupados en uno o más buckets, o de buckets provenientes de otras agregaciones. En términos generales, metrics genera uno o más números que describen los documentos agrupados.
Metrics puede ser del tipo:
Single-value: devuelve solo una métrica.
Multi-value: devuelve más de una métrica.
Vea en la tabla abajo una breve descripción de cada agregación de metrics. La imagen abajo muestra la parte de la pantalla Visualize donde se elige la agregación metrics.
Metrics |
Descripción |
Average (promedio) |
Agregación de metrics de tipo |
Count (contar) |
Esta metric cuenta los documentos presentes en cada uno de los buckets seleccionados. |
Sum (suma) |
Agregación de metric de tipo |
Max |
Agregación de metric de tipo |
Mediana (mediana) |
Agregación de metric de tipo |
Min |
Agregación de metric de tipo |
Percentiles |
Agregación de métricas de tipo |
Percentile ranks |
Agregación de métricas de tipo |
Standard deviation (desviación estándar) |
Representa la variación de un grupo de valores alrededor de la media. Una desviación estándar baja indica que los valores tienden a estar cerca de la media o el valor esperado. |
Top hits |
Agregación de metrics de tipo |
Unique count |
Agregación de metrics de tipo |
Con pipeline aggregations puede concatenar agregaciones usando los resultados de una agregación como entrada para otra agregación.
Las pipeline aggregations permiten cálculos estadísticos más complejos, como derivados, sumas acumuladas y promedios móviles.
Parent pipeline: pipeline aggregation en la que los resultados de una agregación padre se utilizan para calcular nuevos buckets o nuevas agregaciones que se agregarán a los buckets existentes. Se requiere que min_doc_count para la parent pipeline sea 0, que es el valor predeterminado para las agregaciones de tipo histograma. La métrica debe basarse en valores numéricos.
Sibiling pipeline: pipeline aggregation en la que los resultados de una agregación hermana se utilizan para calcular una nueva agregación que estará al mismo nivel que la agregación hermana. Necesariamente, las sibiling pipelines son de tipo multi-value y la métrica debe ser un valor numérico.
Las pipeline aggregations están en la misma lista que las agregaciones de metrics, como se muestra en la imagen a continuación.
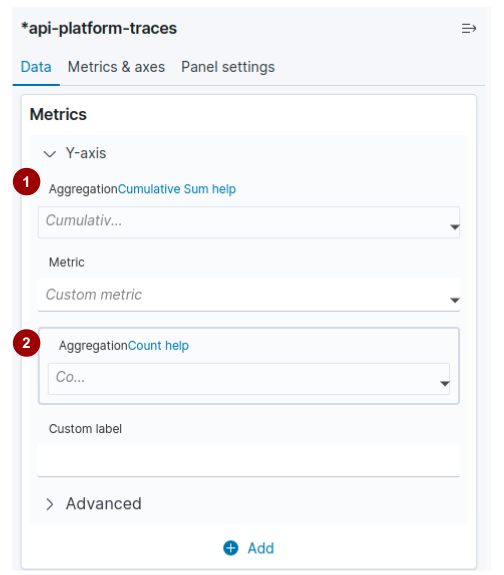
Al seleccionar una agregación pipeline aggregation (identificada como 1 en la figura a continuación), sea parent o sibiling, se abre otro cuadro a continuación para que pueda configurar la segunda agregación (identificada como 2 en la figura a continuación):
Parent pipeline aggregations
Agregación |
Descripción |
Cumulative sum suma acumulativa |
Calcula la suma acumulada de una métrica en una agregación padre de tipo histograma o date histogram. Esta agregación calcula el valor del campo sumando el valor anterior al valor actual. El resultado será un valor único que representa la suma acumulativa de los valores del campo. La métrica debe ser numérica y el histograma añadido debe tener |
Derivative derivada |
Calcula la derivada de una métrica en una agregación padre de tipo histograma o date histogram. La métrica debe ser numérica y el histograma añadido debe tener |
Moving avg promedio móvil |
Encuentra series de medias de diferentes subgrupos (ventanas) de un dataset. Se puede utilizar para suavizar las fluctuaciones o resaltar tendencias o ciclos en datos de tipo time_series. |
Serial diff |
Serial differencing es una técnica que subtrae un valor en una serie de tiempo de sí mismo en un intervalo o período diferente. Primero, debe especificar un histogram o date_histogram para un campo. Luego puede agregar una métrica simple como sum dentro del histograma, luego agregue serial diff al histograma. |
Sibling pipeline aggregations
Agregación |
Descripción |
Average bucket |
Calcula el valor promedio de una métrica específica en una agregación de tipo sibiling. La métrica debe ser numérica y la sibling aggregation debe ser de tipo |
Max bucket |
Identifica lo(s) bucket(s) con el valor máximo de una métrica determinada en una sibling aggregation y devuelve el valor y la clave de lo(s) bucket(s). La métrica debe ser numérica y la agregación de hermanos debe ser del tipo |
Min bucket |
Identifica lo(s) bucket(s) con el valor mínimo de una métrica dada en una sibling aggregation y devuelve el valor y la clave de los bucket(s). La métrica debe ser numérica y la sibling aggregation debe ser del tipo |
Sum bucket |
Calcula la suma de todos los buckets de una métrica determinada en una sibling aggregation. La métrica debe ser numérica y la sibling aggregation debe ser de tipo |
Share your suggestions with us!
Click here and then [+ Submit idea]