Thanks for your feedback!
EDIT
Para garantizar un rendimiento rápido y estable para todos los usuarios, recomendamos firmemente seguir estas buenas prácticas al consultar la Sensedia Analytics API.
Estas recomendaciones son especialmente importantes en entornos de alto volumen y con múltiples consumidores, ya que contribuyen directamente a la estabilidad del clúster, la reducción de latencia y una mejor experiencia general de la plataforma.
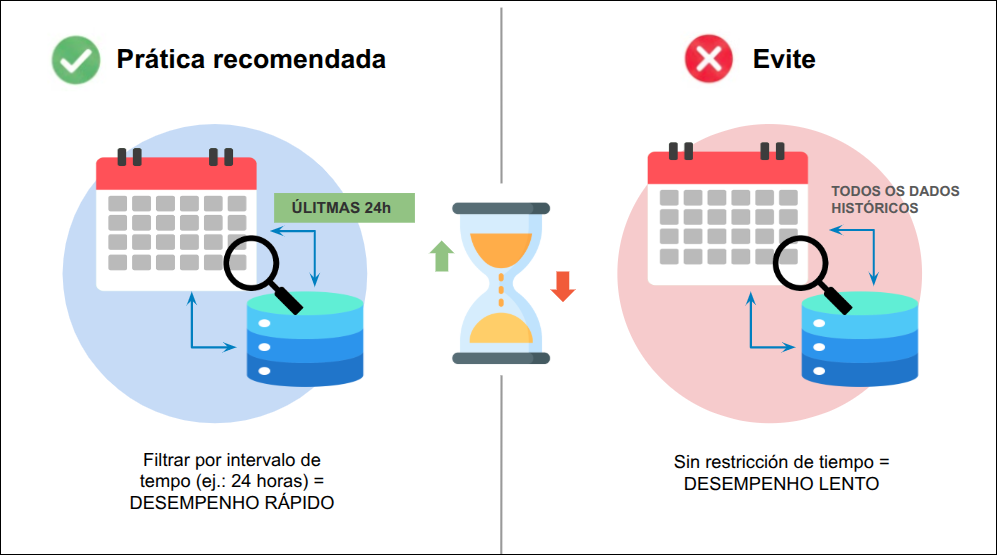
La búsqueda en datos temporales se optimiza cuando los índices siguen el patrón de series temporales (time-series).
Práctica recomendada: Incluya siempre un filtro de rango de tiempo (range query) en sus consultas.
Evite: Consultas que intentan recuperar datos de todo el historial sin restricciones de tiempo.
Optimización: Limite la consulta al menor intervalo de tiempo necesario. Por ejemplo, consultar 24 horas de datos es significativamente más rápido que consultar 30 días.

Restringir el número de documentos devueltos en una sola solicitud es fundamental para el rendimiento de la red y la eficiencia de la búsqueda.
Use paginación:
Utilice parámetros como size y from (o page y limit) para controlar la cantidad de resultados y el desplazamiento de la consulta.
Límites inteligentes:
Mantenga el size (límite de documentos por solicitud) en un valor razonable, por ejemplo, un máximo de 1.000 o 10.000 registros, de acuerdo con la capacidad de su entorno.
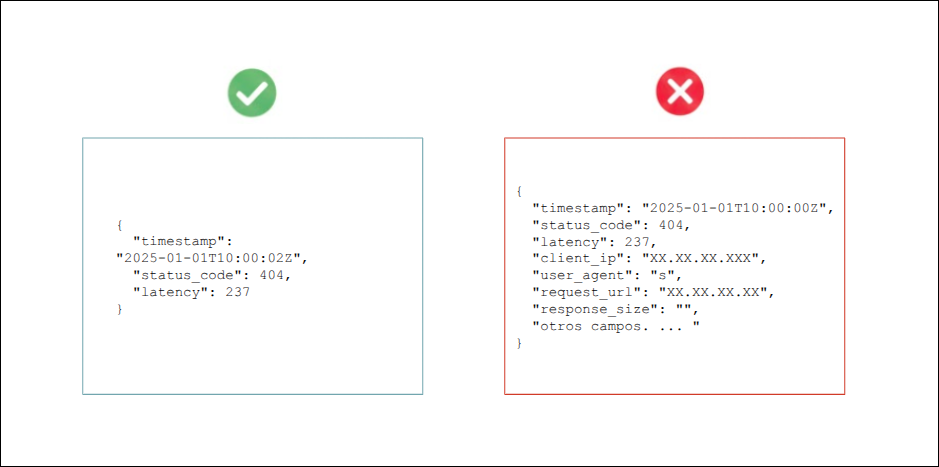
De forma predeterminada, OpenSearch devuelve el documento JSON completo (_source).
Si su aplicación solo requiere un subconjunto de campos, especifique explícitamente cuáles necesita.
Use _source_includes o parámetros de campos:
Solicite únicamente los campos que serán utilizados, por ejemplo: fields=timestamp,status_code,latency.
Beneficio: Esto reduce significativamente el consumo de ancho de banda y el tiempo de procesamiento en el clúster OpenSearch.
Las agregaciones se utilizan para calcular métricas como conteos, promedios y sumas, y suelen representar la parte más costosa de una consulta.
Filtre antes de agregar:
Aplique siempre filtros estrictos — especialmente el filtro de tiempo — antes de ejecutar las agregaciones.
Cuantos menos documentos deban procesarse, más rápida será la respuesta.
Evite agregaciones de alta cardinalidad:
Evite agrupar por campos con un número extremadamente alto de valores únicos, como los identificadores de transacción.
Prefiera campos con cardinalidad controlada, como status_code o api_name.
Limitación de buckets: No solicite un número excesivo de buckets en una sola agregación. Si necesita más de 100 buckets, considere realizar múltiples consultas o utilizar técnicas de muestreo.
La forma en que se estructuran las búsquedas impacta directamente en el rendimiento.
Selección correcta del tipo de consulta:
Utilice term exclusivamente para coincidencias exactas en campos del tipo keyword y match para búsquedas de texto completo en campos analizados, evitando el procesamiento innecesario de texto.
Evite el uso de consultas wildcard (*) o expresiones regulares siempre que sea posible, ya que requieren un escaneo intensivo del índice y consumen significativamente más CPU y I/O.
Si debe usar wildcard:
Evite iniciar la expresión con "*".
Por ejemplo, prefiera api_name* en lugar de *api_name.
Ordenar los resultados es una operación costosa y debe evitarse siempre que sea posible.
Práctica recomendada: Si la ordenación predeterminada por timestamp en orden descendente es suficiente, evite especificar campos adicionales para ordenar.
Cuando sea necesario ordenar:
Prefiera campos numéricos o de fecha que no sean analizados (campos de tipo keyword).
Evite ordenar por campos de texto no estructurado.
Siguiendo estas directrices, sus clientes maximizarán el rendimiento de las consultas y ayudarán a mantener el funcionamiento óptimo de Sensedia Analytics.
Share your suggestions with us!
Click here and then [+ Submit idea]