Thanks for your feedback!
EDIT
Aggregations build on complex searches, providing faster results and being easier to perform. Several searches are aggregated to be analyzed, computed and displayed as a single request.
Compared to queries, aggregations consume more CPU and memory.
Every aggregation is a combination of one or more buckets and zero or more metrics.
Read more about:
Buckets create groups of documents based on certain criteria, depending on the aggregation type. The name derives from the concept of gathering documents into containers/buckets. Buckets don’t calculate metrics like metrics do.
For example, the date 2022-12-19 would be in a bucket for December and the city of Campinas, in a bucket for the state of São Paulo.
Buckets can be contained within other buckets. For example, Campinas would be in a bucket for the state of São Paulo and the entire bucket of São Paulo would be in a bucket for Brazil.
See the table below for a description of the main types of buckets. The image below shows the list from which to choose a bucket type (located in the right side of the Visualize screen). See also how to create a new visualization and learn how to get to this screen to choose the type of buckets.
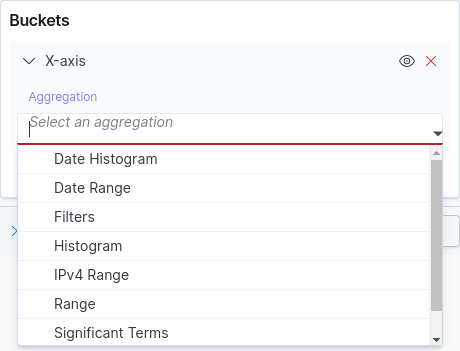
Type |
Definition |
Parameters |
Histogram |
Dynamically groups documents into buckets based on specific intervals (numeric values or numeric range values). It is similar to range aggregation; however, instead of defining each range specifically, you may activate the |
Minimum interval: Select Use auto interval or specify the minimum interval. |
Date histogram |
Similar to the regular histogram aggregation, but exclusive for date values or date range values. |
Minimum interval: specify the minimum rounding interval. By default, |
Range |
Defines a set of intervals, each representing a bucket. Each document is checked according to the variation range of its interval and grouped according to its relevance or correspondence to this range, which can be numeric, based on date values or on IP address. Usage example: When searching for a certain type of product in an online store, range can display the most popular price range for that type of product. |
|
Date range |
A range aggregation specific for date values. |
Acceptable date formats: inform a start and end for each range. |
Filters |
Aggregation in which each bucket contains documents that match a query. It is possible to define more than one filter. |
Filter: provide the search expression. It can be written in DQL or Lucene. Click + Add filter to add another filter. |
NOTE: Select Lucene or DQL and use the corresponding syntax. For a query written in Lucene to be interpreted correctly, Lucene must be selected. The same is true for DQL. |
||
Terms |
Group by categories and retrieve the total number of documents in each category. That is, terms tells you the number of times a given term appears in your documents. |
Order by: defines the ordering type, based on the metric selected, which can be: |
Significant terms |
Returns occurrences of interesting or unusual terms. The result shown is the difference between the occurrence of a term in every index and the occurrence of the same term in your queries, highlighting the terms that are relevant within each search context. For example, the term "sensedia" would be relevant in the context of "apis". |
Size: select how many term buckets should be returned from the total list of terms. |
Both metrics and buckets aggregations allow you to add advanced parameters.
To access advanced parameters, click the expand/collapse icon next to Advanced, as shown in the image below.
Depending on the type or field selected for the aggregation, in addition to the JSON input field, different options may be available for entering or selecting data.
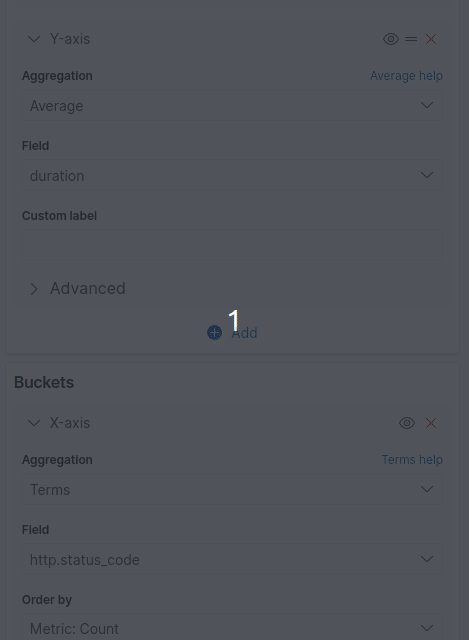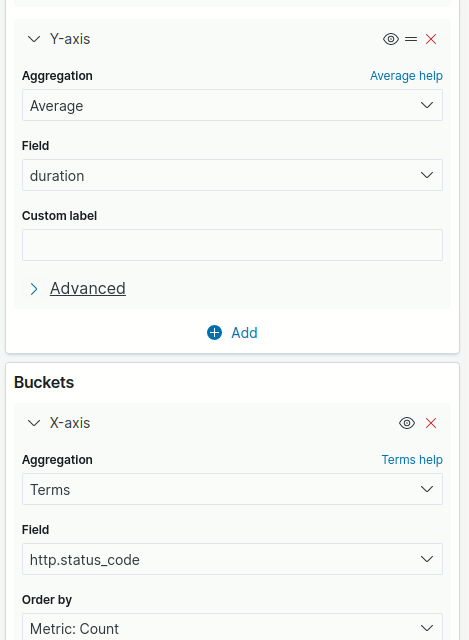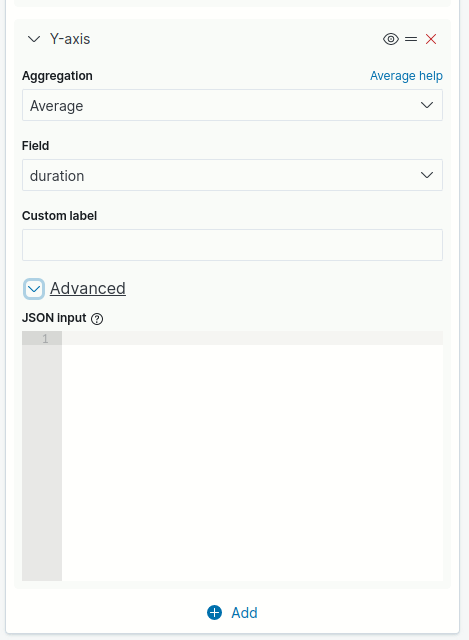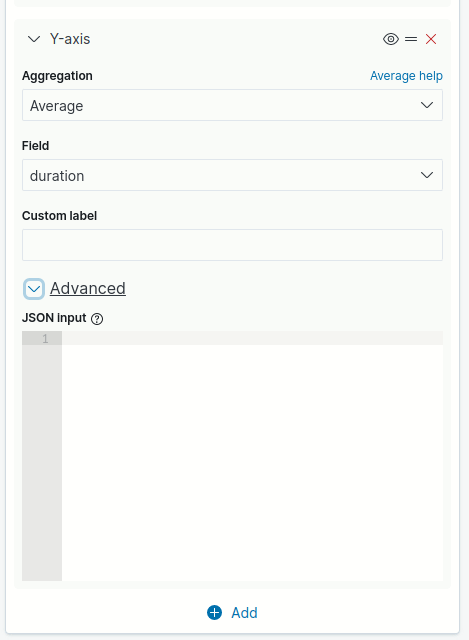
See the table below for definitions and usage examples for the main advanced parameters used with bucket aggregations.
The definitions of each bucket aggregation type and its basic parameters are in the previous table.
Type |
Advanced Parameters |
Date Histogram |
|
Range and Date range |
"missing": "11/30/1976",
"ranges":[
{
"key": "Older",
"to": "2015/01/01"
},
]
|
Filters |
|
Histogram |
"histogram": {
"field": "quantity",
"range": 10,
"missing": 0
}
"extended_bounds" : {
"min" : "2014-01-01",
"max" : "2014-12-31"
}
|
Terms and Significant terms |
|
Metrics extract statistics from documents grouped into one or more buckets or from buckets resulting from other aggregations. Generally speaking, metrics generate one or more numbers that describe the grouped documents.
Metrics can be:
Single-value: returns only one metric.
Multi-value: returns more than one metric.
See the table below for a brief description of each metric. The image below shows the part of the Visualize screen where you can select a metric.
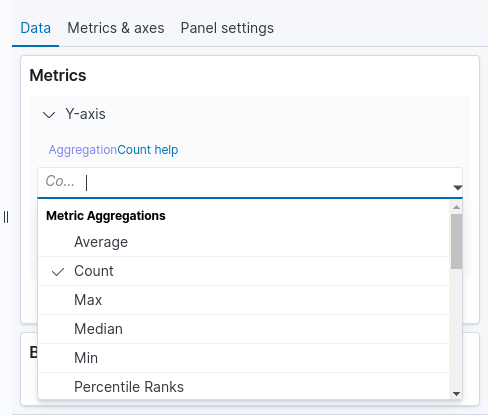
Metrics |
Description |
Average |
|
Count |
This metrics aggregation counts the documents present in each of the selected buckets. |
Sum |
A |
Max |
A |
Median |
A |
Min |
A |
Percentiles |
A |
Percentile ranks |
A |
Standard deviation |
Represents the variation of a group of values around the mean. A low standard deviation indicates that the values tend to be close to the mean or expected value. |
Top hits |
A |
Unique Count |
A |
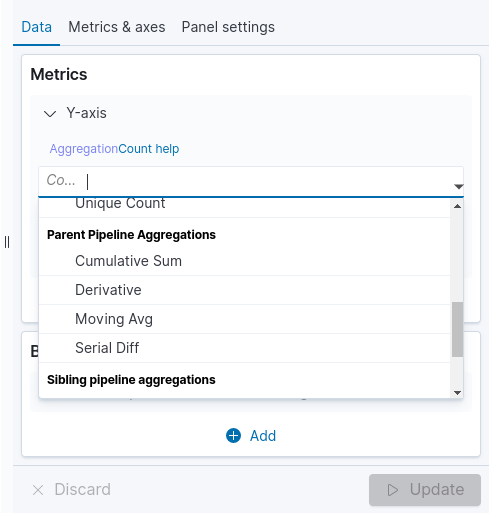
With Pipeline Aggregations you can concatenate aggregations using the results of one aggregation as input to another aggregation.
Pipeline aggregations enable more complex statistical calculations, such as derivatives, cumulative sums, and moving averages.
Parent pipeline: pipeline aggregation in which the results of a parent aggregation are used to calculate new buckets or new aggregations that will be added to existing buckets. The min_doc_count for parent pipeline aggregations must be set to 0, which is the default for histogram aggregations. The metric must be a numeric value.
Sibling pipeline: pipeline aggregation in which the aggregation uses the results of a sibling aggregation to compute a new aggregation that will be at the same level as the sibling aggregation. Necessarily, sibling pipelines must be multi-value and the metric, a numerical value.
Pipeline aggregations can be found in the same list as the Metrics aggregations, as shown in the image below.
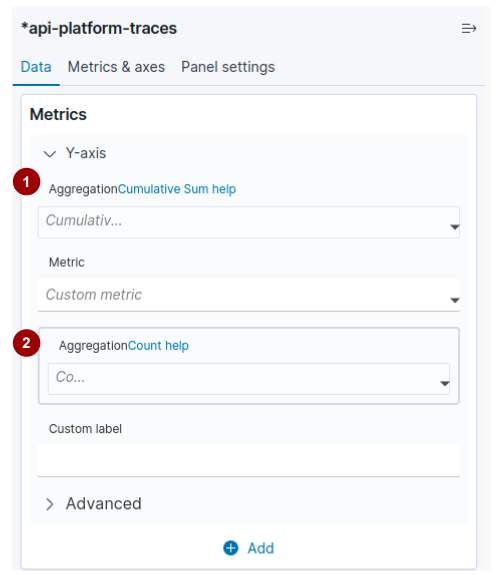
When selecting a pipeline aggregation (identified as 1 in the figure below), whether it is parent or sibling, another box opens so that you can configure the second aggregation (identified as 2 in the figure below).
Parent pipeline aggregations
Aggregation |
Description |
Cumulative sum |
Calculates the cumulative sum of a metric in a parent histogram or parent date histogram aggregation. This aggregation calculates the field value by adding the previous value to the current one. The result will be a single value representing the cumulative sum of the field values. The metric must be numeric and the added histogram must have |
Derivative |
Calculates the derivative of a metric in a parent histogram or date histogram aggregation. The metric must be numeric and the added histogram must have |
Moving avg |
Finds the series of averages of different subgroups (windows) of a dataset. Can be used to smooth out fluctuations or to highlight trends or cycles in time series data. |
Serial diff |
Serial differencing is a technique that subtracts a value from itself in a time series, at a different interval or period. First, you need to specify a histogram or date histogram for a field. Then you can add a simple metric like sum inside the histogram and add the serial diff to the histogram. |
Sibling pipeline aggregations
Aggregation |
Description |
Average bucket |
Calculates the average value of a specified metric in a sibling aggregation. The metric must be numeric and the sibling aggregation must be a |
Max bucket |
Identifies the bucket or buckets with the maximum value of a given metric in a sibling aggregation and returns the value and key for that bucket. The metric must be numeric and the sibling aggregation must be a |
Min bucket |
Identifies the bucket or buckets with the maximum value of a given metric in a sibling aggregation and returns the value and key for that bucket. The metric must be numeric and the sibling aggregation must be a |
Sum bucket |
Calculates the sum across all buckets of a given metric in a sibling aggregation. The metric must be numeric and the sibling aggregation must be a |
Share your suggestions with us!
Click here and then [+ Submit idea]